C# plugin and reading text content, characters missing when too quickly after a user edit
-
public unsafe void SetText(string text) { if (text.Length == 0) { ClearAll(); return; } fixed (byte* textPtr = Encoding.UTF8.GetBytes(text)) { Win32.SendMessage(scintilla, SciMsg.SCI_SETTEXT, (IntPtr) Unused, (IntPtr) textPtr); } }Are you sure that textPtr is a null terminated “string” pointer? I assume it is not.
-
This does not seem correct either
private unsafe string GetNullStrippedStringFromMessageThatReturnsLength(SciMsg msg, int length = 0) { if (length < 1) length = Win32.SendMessage(scintilla, msg, (IntPtr)Unused, (IntPtr)Unused).ToInt32(); byte[] textBuffer = new byte[length]; fixed (byte* textPtr = textBuffer) { Win32.SendMessage(scintilla, msg, (IntPtr)length, (IntPtr)textPtr); int lastNullCharPos = length - 1; // this only bypasses NULL chars because no char // other than NULL can have any 0-valued bytes in UTF-8. // See https://en.wikipedia.org/wiki/UTF-8#Encoding for (; lastNullCharPos >= 0 && textBuffer[lastNullCharPos] == '\x00'; lastNullCharPos--) { } return Encoding.UTF8.GetString(textBuffer, 0, lastNullCharPos + 1); } }If length is 0 or less, the required null-terminating byte is missing, right? Means, the stack/heap might get corrupted.
-
Hmmm … as far as I can tell, I see a few problems in the original scintilla wrapper code.
It often casts to int where intptr actually belongs. This may be due to internal C# issues, but is that, in 2025, really still the case? -
@Ekopalypse said in C# plugin and reading text content, characters missing when too quickly after a user edit:
It often casts to int where intptr actually belongs.
Agreed that this is done a lot, but never in cases where the
IntPtrreturned is a a location in memory. It is more convenient for the developer to use anint.Obviously some methods like
SCI_GETLENGTHcould potentially return a number greater thanint.MaxValue, but that is exactly why I implementedNpp.TryGetLengthAsIntandNpp.TryGetText: to make it easy for developers to bail out and stop executing a plugin command on files that are too big. It is literally impossible for a C# string to have length greater thanint.MaxValue, after all.@Ekopalypse said in C# plugin and reading text content, characters missing when too quickly after a user edit:
Are you sure that textPtr is a null terminated “string” pointer? I assume it is not.
Yeah, that’s an issue that I need to fix. Thank you for pointing this out! I’ll find all the places where a null terminated string is required and adjust the code where appropriate.
-
After carefully consulting the Scintilla documentation, I believe that this NppCSharpPluginPack commit ought to fix the issue @Ekopalypse mentioned where in some cases I was supposed to be sending a null-terminated string to Notepad++ but wasn’t.
As far as I can tell, in every other situation where I send a string to Notepad++ I am also sending the length and thus the string can contain NUL characters.
-
@Ekopalypse @Mark-Olson Thanks for looking into this and your insights. I’ve been using the ScintillaGateway source files as provided and tbh I don’t fully understand what it all does. Looking at the NppCSharpPluginPack commit and my ScintillaGateway.cs I think there have been some fixed along the way of developing the CSV plugin and I’ve got an outdated or different source files.
I suspect there’s not some easy fix for this issue and it’s better to move the whole CSV Lint project from using the VS2019 NotepadPlusPlusPluginPack.Net to using the newer NppCSharpPluginPack. That will take some reworking but then we’re at least all working with the same baseline source files.
-
@Mark-Olson said in C# plugin and reading text content, characters missing when too quickly after a user edit:
After carefully consulting the Scintilla documentation, I believe that this NppCSharpPluginPack commit ought to fix the issue @Ekopalypse mentioned where in some cases I was supposed to be sending a null-terminated string to Notepad++ but wasn’t.
If I’m following correctly, the return value of this method is the “null-terminated string” of the commit message (where
+ 1accounts for theNULL, I’m guessing):private byte[] GetNullTerminatedUTF8Bytes(string text) { int length = Encoding.UTF8.GetByteCount(text); byte[] bytes = new byte[length + 1]; int lengthWritten = Encoding.UTF8.GetBytes(text, 0, text.Length, bytes, 0); // ... return bytes; }Looks good. But what if the given document is not UTF8, but ANSI or UTF-16?
Notepad++ calls “ANSI” whatever the system’s default encoding happens to be, which is the same code page mapped to
System.Text.Encoding.Default, and can be looked up withreg query HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage /v ACP.Here’s the string
"café\0", with theNULLcharacter already included:Microsoft (R) Visual C# Interactive Compiler version 4.14.0-3.25326.11 () Copyright (C) Microsoft Corporation. All rights reserved. Type "#help" for more information. > using static System.Text.Encoding; > UTF8.GetByteCount("café\0") 6 > Default.GetByteCount("café\0") 5Now, the type of string returned by most N++ API methods is
wchar_t*, which is UTF-16 on Windows. The .NET equivalent of UTF-16 isSystem.Text.Encoding.Unicode; here’s the length in bytes of a singleNULLcharacter in UTF-16:> Unicode.GetByteCount("\0") 2 > // in fact... > System.Runtime.InteropServices.Marshal.SystemDefaultCharSize == Unicode.GetByteCount("\0") trueWhich means the string
"café\0"has 2 possible byte lengths depending on the document’s encoding: 5 for ANSI and 6 for UTF8. If we were getting text from an N++ API and inserting that into the document, the length would be something else again:> Unicode.GetByteCount("café\0") 10In other words, a
NULLcharacter is not guaranteed to always be the same length as aNULLbyte.A more comprehensive fix would involve querying the current document’s encoding (e.g., using SCI_GETCODEPAGE), then creating an instance of
System.Text.Encodingusing, for example, System.Text.Encoding.GetEncoding(Int32), with a fallback in case of exceptions, e.g.:- int length = Encoding.UTF8.GetByteCount(text); - byte[] bytes = new byte[length + 1]; + // assign the .NET equivalent of the document's encoding to "cp" + int length = cp.GetByteCount(text); + byte[] bytes = new byte[length + cp.GetByteCount("\0")];For a fully worked-out example, see this implementation of encoding-aware Scintilla wrappers for .NET. The code is multi-targeted, so it should be possible to copy-paste any part of it into a .NET Framework project.
-
Just to make clear what the issue is, see screenshots below, so
A) Open the file and notice the text “test123@my.”
B) make one edit, like change “test123@my.” to “test12@my.”
C) quickly open Reformat dialog and press OK, like within 2 secondsNow one extra character after the edited part is missing, so “test12@my.” becomes “test12my.”
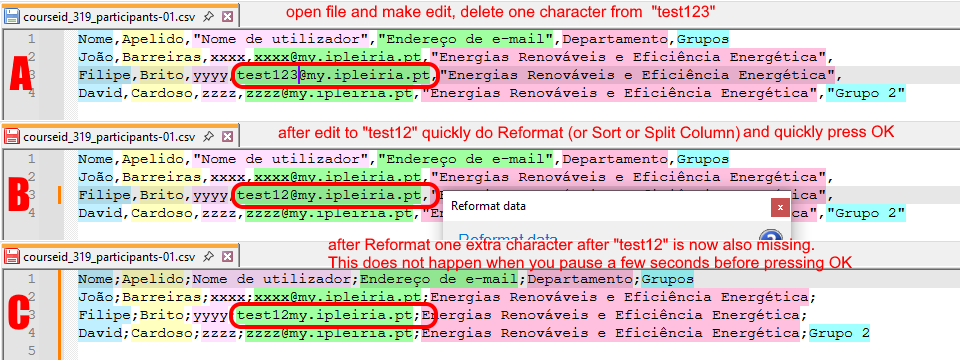
It always hapens at the point of the edit, and it only happens when you do it very quickly, like within about 2 seconds. In other words, when you make the edit, open the Reformat dialog, wait 5 seconds, then press OK, then it doesn’t happen.
Can something like that really be explained by a string encoding issue? I mean, why does it not happen when you wait a few more seconds?
-
Can something like that really be explained by a string encoding issue?
I agree with you that this is pretty clearly a race condition, and not an encoding issue.
If you’re having a problem with ScintillaStreams while the document is being edited, it seems like the simplest option would be to do something like I do in JsonTools with automatic linting after edit where I track the last time the document was edited and wait to do some operations until the user hasn’t edited for a while. But the only way I can see to do a non-blocking wait from when the user presses a button until some condition is met is to spawn a new thread that keeps sleeping and checking the condition until that condition is met.
I guess my feeling is that
ScintillaGateway.GetTextis a superior option to ScintillaStreams for reformatting, because if the user is using their plugin to reformat their file, the only sane thing for them to do is wait until the reformatting is done, and a blocking function forces them to do this. I can see why you prefer ScintillaStreams for just getting a CSV schema or any other read-only operation, since not blocking the editor is worth being off by a character or two. -
But what if the given document is not UTF8, but ANSI or UTF-16?
I’ve finally gotten around to implementing a fix for this issue in JsonTools. I did this first in JsonTools because it has a lot of features that read the text of the file. It appears to work fine for ANSI files (you can test it on this example file I added).
As I noted in the commit message, there are some features that are broken because my JSON parser’s code for determining node position assumes that the document is UTF8-encoded.
…or UTF-16?
JsonTools has always worked correctly on files with any encoding except ANSI, so at least on my machine, I have just confirmed that Notepad++ internally represents documents as UTF-8 if the file itself is in UTF-16 or some exotic encoding like OEM 865.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login