Names of character sets
-
@Paul-Wormer said in Names of character sets:
The Npp character panel says on top “ASCII codes”. As is well-known “ASCII” is a 7-bit code that on the IBM-PC was extended to an 8-bit code by adding codepoints 128 to 256. The IBM code differs from the Windows CP1252 character set. I believe - but I did not check all characters - that the Npp control panel contains CP1252 characters. This set differs in codepoints 128 - 159 from Unicode Latin-1. In Latin-1 the codepoints 128-159 represent (unprintable) control characters.
… Further, this paragraph by you implies that you think the Edit > Character Panel always shows the same 256 characters. You would be wrong.
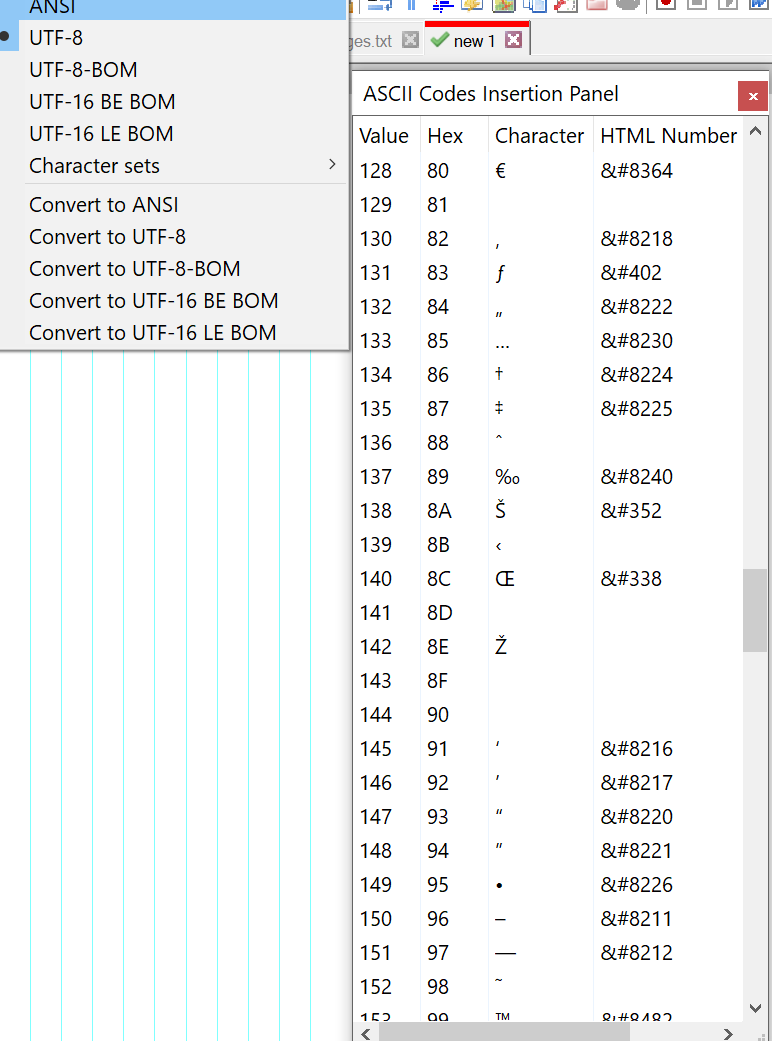
It shows the 256 characters for whatever the active codepage is (or the first 256 codepoints from Unicode for UTF-8 or UTF-16:
UTF-8:
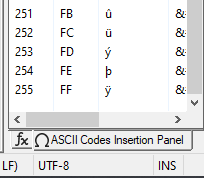
ANSI (on my system, where chcp 1252 is the default):
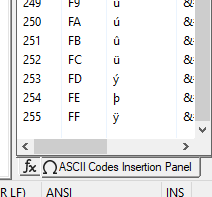
Character Set > Western > OEM-US:
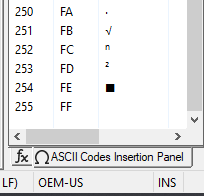
Character Set > Thai > TIS-620 (picked at random):
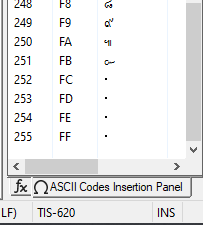
…
And to find out what your computer considers the “ANSI”, look at the ? > Debug Info:
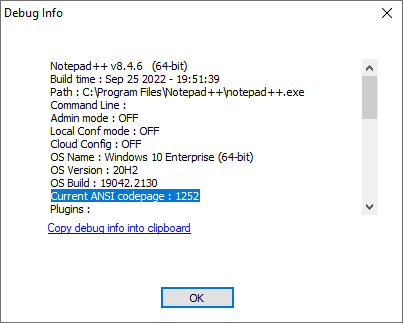
It lists the “Current ANSI codepage”. -
@PeterJones
OK, so the debug page states “Current ANSI codepage : 1252”, confirming what I thought. However, I did not know that you could set an active code page. Apparently it is not set by the entry in the tab “Encoding” because I almost always have “UTF-8” there. -
@Paul-Wormer said in Names of character sets:
However, I did not know that you could set an active code page
That’s a Windows setting. In a cmd.exe prompt, you can change the codepage using
chcp– but that doesn’t affect the Notepad++ “Current ANSI codepage”, even if you run Notepad++ from that cmd.exe window.Your system’s default codepage (the one that Notepad++ shows) is based on your language settings in your Windows OS.
-
@Paul-Wormer said in Names of character sets:
so the debug page states “Current ANSI codepage : 1252”
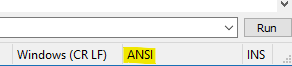
That tells you what you are looking at when you have this in your status bar:
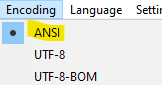
And this if you drop the Encoding menu:
What’s in the Debug Info shows you what Windows has for your system’s codepage; Notepad++ just follows it.
BTW, when your Debug Info codepage is “1252”, the following are equivalent to “ANSI” in the screenshots above:
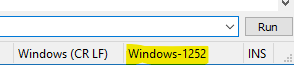
which you would obtain from choosing:
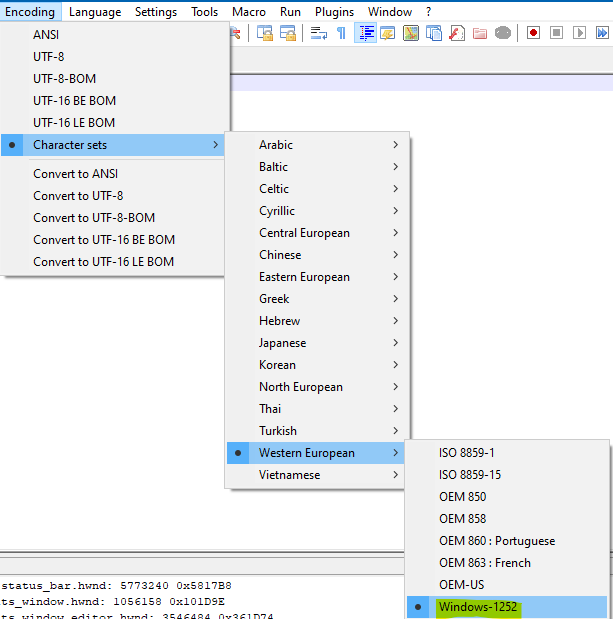
-
@Alan-Kilborn Thank you for pointing out this route to character sets. It is interesting to find the entry “OEM-US” under the heading “Western European”. This sets the clock back to 1776.
When I select the OEM-US entry, the Edit > Character Panel shows the characters of the original IBM-PC extended ASCII set (CP 437). IMHO, CP 437 (or OEM 437) would be more telling than OEM-US and also more consistent with OEM 850 (the European counterpart of CP 437).
Incidentally, Windows’ charmap refers to CP 437 as “DOS: United States” and to CP 850 as “DOS: Western Europe”. Wouldn’t it be a good idea if N++ followed the nomenclature of the Windows charmap?
-
@Paul-Wormer said in Names of character sets:
CP 437 (or OEM 437) would be more telling than OEM-US
See HERE for some also-known-as’s.
It is interesting to find the entry “OEM-US” under the heading “Western European”
I found that strange as well; I have no explanation for why it was slotted under that.
-
@PeterJones As Alan Kilborn pointed out, one can change code pages within N++ (under Encoding). I played around a little with it and found that often Edit > Character Panel followed the setting of the code page, but not consistently. Is there a kind of systematics that I overlook?
-
@Paul-Wormer said in Names of character sets:
found that often Edit > Character Panel followed the setting of the code page, but not consistently
Please give an example of the inconsistency.
-
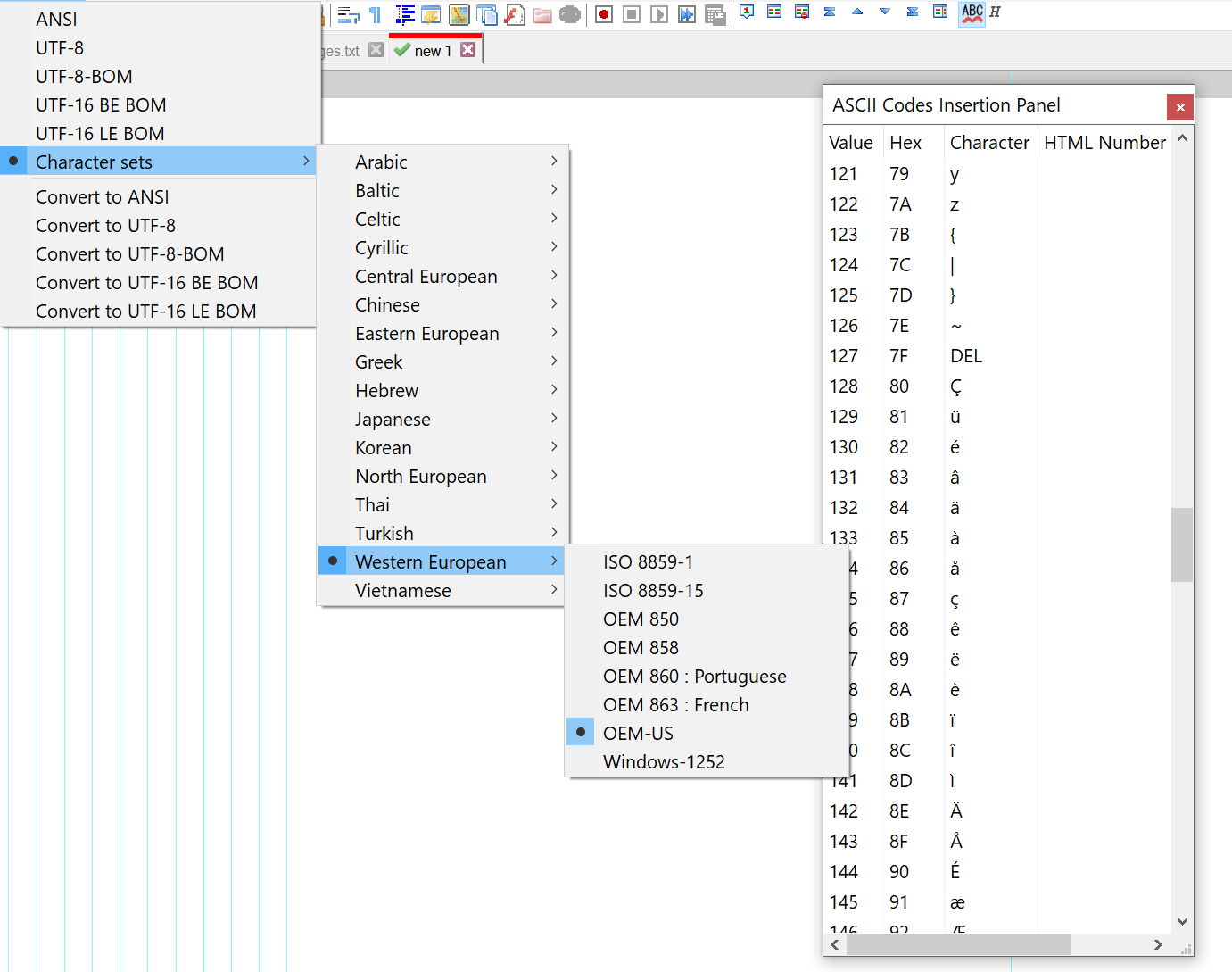
As you know 0x80 is a good character to concentrate on. In UTF8 it is a control character, in CP1252 it is € and in CP 437 it is Ç. I showed results of one edit session. First UTF8 that shows the character panel of CP1252 and then OEM-US that shows CP 437.
-
Hmm, not exactly sure what you’re getting at, but if I use the Character Panel to insert the “0x80” character into a UTF-8 file (and I think the accurate way to say that is, insert a U+0080 character), I visually obtain the
€character (as I would expect), and if I save the file and open it in a hex editor I see the 3-byte combinationE2 82 AC(which I also expect). So I don’t see anything unexpected or inconsistent here, but maybe I’m just missing what you’re trying to say. -
@Alan-Kilborn I would like to see the character panel that agrees with my choice of character set. For instance, if I choose UTF8, I like to see a panel with control codes (no letters) between 0x80 and 0xa0. Or, as in Windows charmap, the control characters may be simply skipped in the panel. In other words, I would like to see more or less the same character panels as in charmap.
Now it seems from the panel as if the € sign has the code 0x80 in UTF8. And, as you correctly point out, it has a 3-byte code, not a 1-byte code in UTF8. BTW, the official Unicode code point of € is 0x20AC, the 3-bytes: E282AC give its UTF8 coding.
-
This post is deleted! -
UTF-8 and UTF-16 seem to be “oddities”. The character sets all just show what’s at the 255 individual codepoints for that character set. But my guess with the UTF-# encodings, because “unicode” handling was an afterthought about halfway through the Notepad++ lifecycle, is that Don just left those there in the UTF-# character panels to show the character from the nth position in Win-1252, but map it to the correct codepoint in Unicode, with the correct bytes for the UTF-# encoding. This would have made it easier for people to transition from Win-1252 to Unicode/UTF-8, while still being able to find their “favorite” characters at the same location in the Notepad++ Character Panel.
Personally, it doesn’t annoy me, because I found the character panel not overly helpful for the Unicode encodings. I have a Notepad++ Run-menu entry to bring up charmap.exe. If I were going to recommend changes to the Character Panel (other than fixing the compiled and english.xml and english_customizable.xml name to be just “Character Panel” that Alan uses) would be to allow it to have multiple “subpages” on the UTF-8/UTF-16 encodings, just like charmap.exe “group by unicode subpage” does, so that you can access more than 255 characters in the Character Panel
-
@PeterJones said in Names of character sets:
because “unicode” handling was an afterthought about halfway through the Notepad++ lifecycle
Well, the transition from a 1-byte character set to a variable-byte character set seems to my layman’s eye more than an afterthought.
I don’t know anything about coding of Windows apps, but couldn’t N++ simply interface with charmap.exe?
-
@Paul-Wormer said in Names of character sets:
@PeterJones said in Names of character sets:
because “unicode” handling was an afterthought about halfway through the Notepad++ lifecycle
Well, the transition from a 1-byte character set to a variable-byte character set seems to my layman’s eye more than an afterthought.
It was a detailed afterthought… but it wasn’t part of the original design of Notepad++ (in the old days, you used to have to download a separate unicode executable vs the standard ANSI executable). And the unicode updates to the character panel do look to me like they were just trying to make something look the same as the WIN-1252/ANSI panel, but mapping those same characters to the UTF-8 or UTF-16 encoding.
I don’t know anything about coding of Windows apps, but couldn’t N++ simply interface with charmap.exe?

I don’t think Windows win32-api provides the charmap.exe interface as a widget, unlike the color picker or other such tool. And since you can easily save a run-menu entry and assign a keyboard shortcut to run
charmap.exe, doing fancy stuff to embed it seems a waste of time. -
Thanks for the discussion guys. It really helps me to figure out my problem.